Help: Analysis Perspective
Overview
When a potentially suitable transformation has been selected, this perspective can be utilized to compare the transformed dataset to the original input dataset. In the center, this perspective will display the original data (area 1) and a transformation (area 2). Both tables are synchronized, e.g., when they are browsed using the horizontal or vertical scrollbars. The areas 3 and 4, allow to compare statistical information about the currently selected attribute(s).
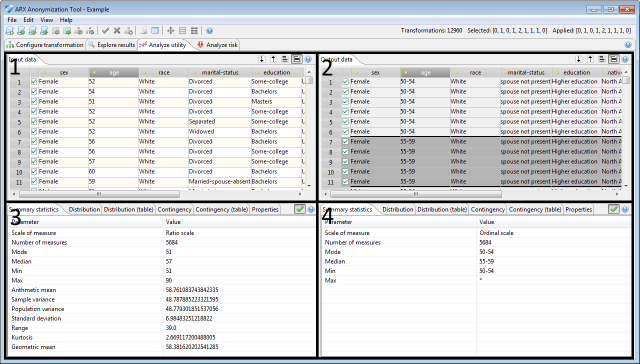
The checkboxes indicate, which rows are contained in the research subset. The checkboxes in the view for the result dataset, indicate the subset that was configured when the anonymization process was performed. They cannot be edited. The checkboxes in the view for the input dataset represent the current research subset and can thus be edited.
Each data view offers a few options, that are accessible via buttons in the top-right corner of the data view:
- The first button will sort the data according to the currently selected column
- The second button will sort the output dataset according to all quasi-identifiers and then highlight the equivalence classes
- The third button will toggle whether all rows of the dataset are displayed or only the current research subset