Help: Perspectives
Overview of the different perspectives
The ARX anonymization tool is divided into four perspectives, which model different aspects of the anonymization process. As is depicted in the Figure shown below, these steps consist of 1) configuring privacy criteria and transformation methods, 2) exploring the solution space and 3) analyzing data in terms of utility and re-identification risks. In the configuration phase, input data is loaded, transformation rules are imported or created and all further parameters, such as privacy criteria, are specified. When the solution space has been characterized by executing an anonymization algorithm, the exploration phase supports searching for privacy-preserving data transformations that fulfill the user's requirements. To assess suitability, the utility analysis phase allows comparing transformed datasets to the original input dataset with methods of descriptive statistics. Finally, risk-analyses can be performed for input datasets as well as their transformed representations. Based on these analyses, further solution candidates might be considered and analyzed, or the configuration of the anonymization process can be altered.
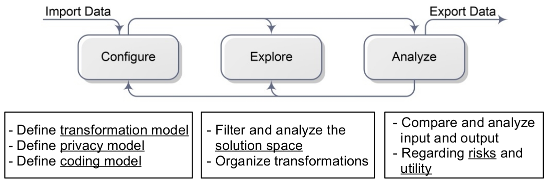
Configuring the privacy model, transformation model and utility measures
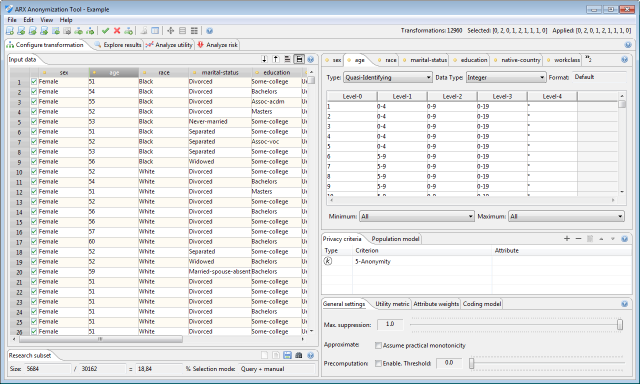
In this section, firstly, a dataset can be imported into the tool and attributes can be characterized. Secondly, generalization hierarchies for quasi-identifiers or sensitive attributes can be generated semi-automatically by means of a wizard or imported into the tool. Thirdly, privacy criteria, the method for measuring data utility and further parameters, such as parameters of the transformation process, can be specified.
Exploration of the solution space
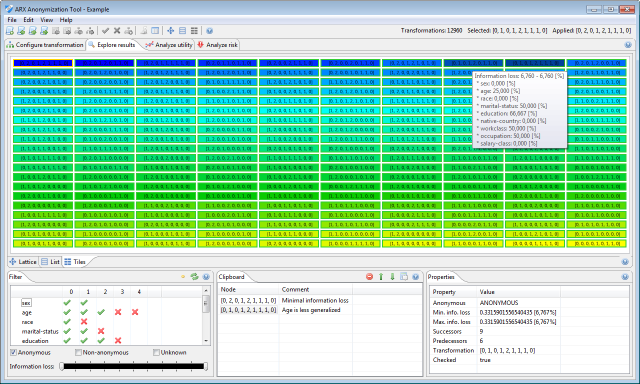
As a result of the anonymization process, a solution space is constructed and characterized based on the given parameters. This perspective allows users to browse the space of data transformations, organize and filter it according to their needs and select transformations for further analysis.
Analysis of data utility
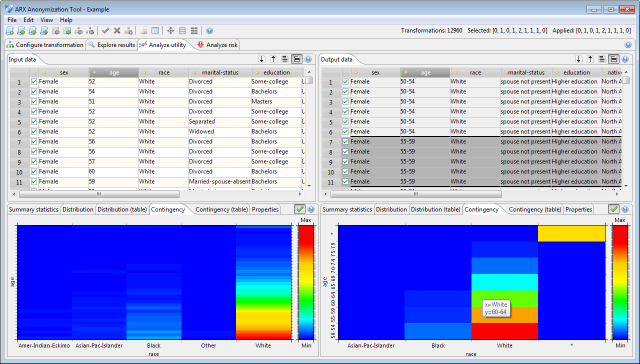
To assess the suitability of a specific transformation for a given usage scenario, this perspective supports comparing transformations of the input dataset to the original data. To this end, it incorporates various graphical representations of results of statistical analyses and also allows for a cell-by-cell comparison.
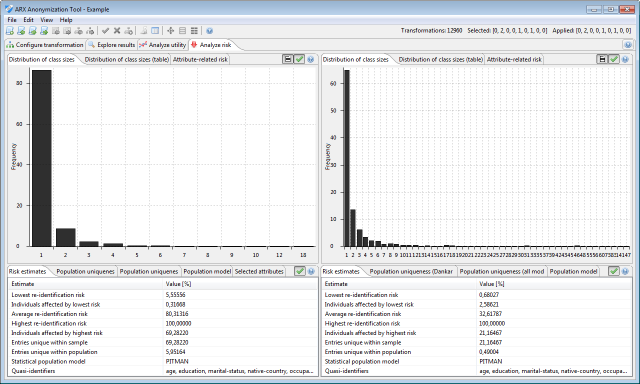
Analysis of re-identification risks
In this perspective, the distribution of class sizes, the risks associated to individual quasi-identifiers, as well as sample-based and population-based risk estimates can be analyzed. The view displays details about the results of estimating uniqueness with different super-population models.
Import and export of data
Generalization hierarchies and datasets can be exported as and imported from files containing character separated values (CSV), which allows to exchange data with common tools such as spreadsheet programs. For loading data into ARX, further data sources are supported. This includes MS Excel spreadsheets and data from relational database systems, such as MS SQL, DB2, MySQL or PostgreSQL. Data import is performed with a dedicated wizard, which is shown in the following image.
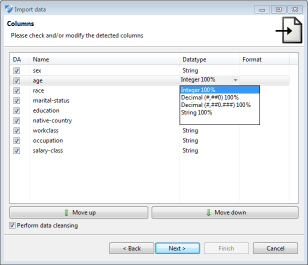
In addition to access to different types of data sources, this wizard supports renaming and hiding columns, as well as changing their order. Data types are automatically detected and data cleansing may be performed. This means that values that do not conform to the selected data type will be replaced with null values. Missing values are handled correctly by all methods provided in the ARX tool.