Help: Settings
General settings (area 4)
In the first tab of this view, general properties of the transformation process can be specified.
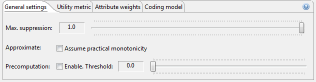
The first slider allows to define the suppression limit, which is the maximal number of outliers that can be tolerated and will be suppressed. The recommended value is "1.0". The option "Approximate" can be enabled to compute an approximate solution with potentially significantly reduced execution times. The solution is guaranteed to fulfill the given privacy model, but it might not be optimal. The recommended setting is "off". For some utility measures, i.e., Non-uniform entropy and Loss, precomputation can be enabled. In this case, the efficiency of computing data utility may increase significantly. With the associated threshold, precomputation may be enabled only for datasets for which it is expected to be effective. Precomputation will only be enabled when, for each quasi-identifier, the number of distinct data values divided by the total number of entries in the dataset is lower than the configured threshold. Experiments have shown that 0.3 is often a good value for this parameter. The recommended setting is "off".
The second tab allows specifying the measure that is to be used for estimating data utility.
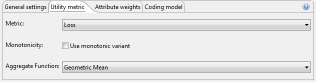
ARX currently supports the following measures. The recommended setting is "Loss":
- Height
- Precision
- Average equivalence class size
- Discernibility
- Non-uniform entropy
- Loss
Monotonicity may be assumed, even for non-monotonic measures. This can significantly speed-up the anonymization process but may lead to unexpected results. The recommended setting is "off". Since version 2.3. ARX also supports user-defined aggregate functions for many measures. These aggregate functions are used for measures in which the loss in utility is computed per quasi-identifier to compile these individual values into a single value. ARX currently supports the following aggregate functions. The recommended setting is "Rank":
- Max
- Sum
- Arithmetic mean
- Geometric mean
- Rank
For most measures, attributes may be weighted as shown in the following tab.
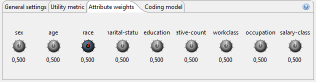
Each of the knobs may be used to associated a weight to a specific quasi-identifier. When solving the anonymization problem, ARX will try to reduce the loss of information for attributes with higher weights.
If "Loss" has been selected for measuring data utility, the coding model that is to be applied by ARX can be further configured in an additional tab.
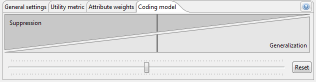
With the slider it can be configured whether ARX should prefer to use generalization or suppression for solving the anonymization problem.