Overview
Overview of supported anonymization methods
ARX is an open source tool for transforming structured (i.e. tabular) personal data using selected methods from the broad areas of data anonymization and statistical disclosure control. It supports transforming datasets in ways that make sure that they adhere to user-specified privacy models and risk thresholds that mitigate attacks that may lead to privacy breaches. ARX can be used to remove direct identifiers (e.g. names) from datasets and to enforce further constraints on indirect identifiers. Indirect identifiers (or quasi-identifiers, or keys) are attributes that do not directly identify an individual but may together with other indirect identifiers form an identifier that can be used for linkage attacks. It is typically assumed that information about indirect identifiers is available to the attacker (in some form of background knowledge) and that they cannot simply be removed from the dataset (e.g. because they are required later for analyses). ARX also supports methods for protecting sensitive attributes from disclosure and semantic privacy models, which require fewer assumptions to be made about the goals and the background knowledge of attackers.
ARX supports (almost) arbitrary combinations the following privacy models:
- Syntactic privacy models, such as k-anonymity, l-diversity, t-closeness, δ-disclosure privacy, β-likeness and δ-presence.
- Statistical privacy models, such as k-map, thresholds on average risk and methods based on super-population models.
- Semantic privacy models, such as (ε, δ)-differential privacy and a game-theoretic de-identification approach.
ARX supports (almost) arbitrary combinations of the following data transformation models:
- Global and local transformation schemes: ARX can apply the same transformation scheme to all records in a dataset or apply different transformation schemes to different subsets of records.
- Random sampling: Privacy risks can be reduced by drawing a random sample from the input dataset.
- Generalization: Records can be made less unique by generalizing attribute values based on user-specified hierarchies.
- Record, attribute and cell suppression: Privacy risks can be lowered by removing individual attribute values or complete records.
- Microaggregation: Clusters of numeric attribute values can be combined into a common value by user-specified aggregation functions.
- Top- and bottom-coding: Values exceeding a user-defined range can be truncated.
- Categorization: Continuous variables can be categorized automatically.
Supported data quality models and objective functions include:
- Cell-oriented models, measuring data granularity and transformation degrees.
- Attribute-oriented models, quantifying deviations in value distributions.
- Record-oriented general-purpose models, quantifying the degree of uniqueness and ambiguity of records, also based on entropy.
- Workload-aware models, measuring the data publisher's benefit and the suitability of output data as a training set for building classification models.
Further details on the privacy and risk models supported by ARX can be found here. Supported data quality models are described in detail here. Information about the data transformation models supported by the software can be found here.
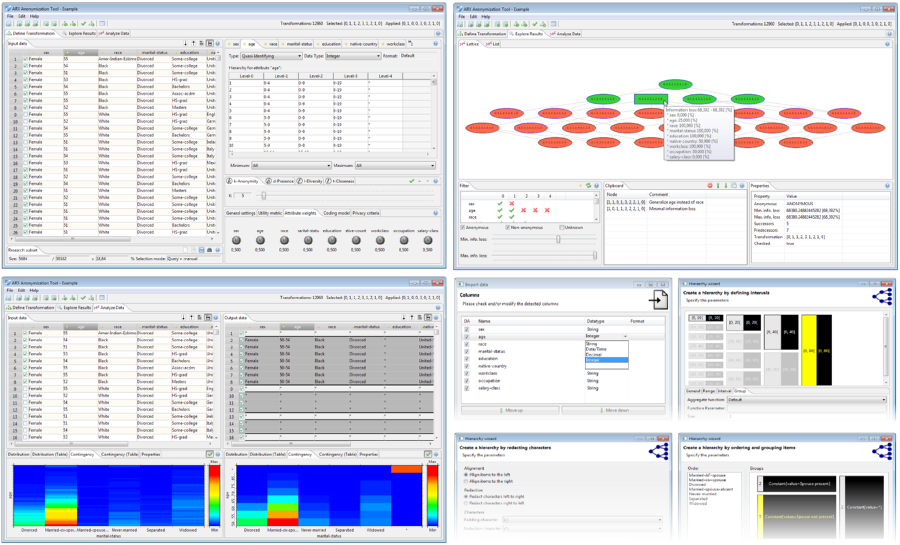
ARX Anonymization Tool
The graphical frontend of ARX provides an intuitive interface and provides various visualizations, wizards and a context-sensitive help. A manual can be found here.
Software Library
The Java software library offers a carefully designed API providing access to all features implemented in ARX.
// Load data
Data data = Data.create("input.csv");
// Set attribute types and load hierarchies
data.getDefinition().setAttributeType("age", Hierarchy.create("age.csv"));
data.getDefinition().setAttributeType("zipcode", Hierarchy.create("zipcode.csv"));
data.getDefinition().setAttributeType("disease", AttributeType.SENSITIVE_ATTRIBUTE);
// Configure the anonymization process
ARXConfiguration config = ARXConfiguration.create();
config.addPrivacyModel(new KAnonymity(5));
config.addPrivacyModel(new EntropyLDiversity("disease", 3));
config.setSuppressionLimit(1d);
config.setQualityModel(Metric.createLossMetric());
// Perform anonymization
ARXAnonymizer anonymizer = new ARXAnonymizer();
ARXResult result = anonymizer.anonymize(data, config);
// Write result
result.getHandle().write("output.csv");
An overview of the API can be found here here. More examples are also available in our GitHub repository.