Help: Criteria
Privacy model (area 3)
This area allows to configure the privacy model and the measure that is to be used for estimating data utility. Privacy criteria can be enabled and disabled by clicking the plus and minus buttons respectively.
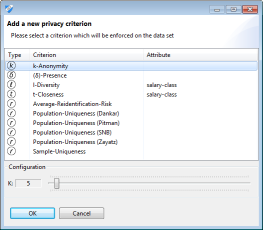
k-Anonymity, d-presence and risk-based criteria apply to all quasi-identifiers and can therefore always be enabled. In contrast, l-diversity and t-closeness are associated with specific sensitive attributes. They can thus only be enabled if a sensitive attribute is currently selected (area 2). Criteria that will be enforced on the dataset are displayed in the table.
k-Anonymity
To specify the parameter of a k-anonymity criterion a slider can be used.
l-Diversity
A dropdown list allows selecting the type of l-diversity that is to be used, i.e., distinct-l-diversity, entropy-l-diversity or recursive-(c,l)-diversity. To specify the parameters of an l-diversity criterion, sliders can be used.
t-Closeness
A dropdown list allows selecting the distance function that should be used for computing the distance between distributions of a sensitive attribute. If "hierarchical distance" is selected, a generalization hierarchy must be specified for the respective attribute. A slider supports specifying the parameter t.
d-Presence
Two sliders can be used for choosing values for d-min and d-max. Note that enabling d-presence also requires specifying a research subset to which it is to be applied (area 5).
Risk-based criteria
To configure risk-based privacy criteria a slider allows selecting a risk threshold. If a popultion-based criterion is used the underlying population model must also be configured (area 3).