Help: Definition Perspective
Overview
In this perspective, firstly, a dataset can be imported into the tool and attributes can be characterized. Secondly, generalization hierarchies for quasi-identifiers or sensitive attributes can be generated automatically with wizards or imported into the tool. Thirdly, the privacy model, the transformation model and the utility measure can be specified and configured.
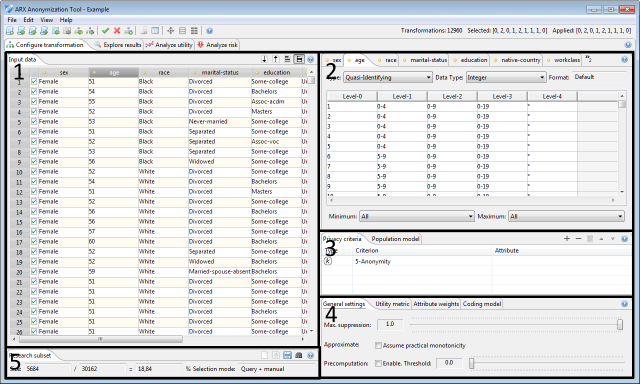
The perspective is divided into five main areas. Area 1 shows the current input dataset, area 2 supports specifying information about its attributes, area 3 supports configuring the privacy model, area 4 supports configuring further properties of the transformation process, such as the coding model, how data utility should be measured and how important certain attributes are. Area 5 allows defining a research dataset, which is a subset of the overall dataset that is to be anonymized and exported.